
0. 我的需求场景
需要将各种资源数据表的数据变动经过一定的转化适配后输入到资源总表总,后续同步到ES中。通过代码埋点的方案,肯定是比较low的,也不容易维护。想通过监听MySQL的binlog来进行处理,进行调研相关组件后,最终选择maxwell落地。
1. 简介
官方网站:https://maxwells-daemon.io/
官方仓库: https://github.com/zendesk/maxwell
maxwell可以读取MySQL的binlog,并将更新以JSON的格式写入Kafka、Redis等的组件。maxwell这类组件常见的应用场景有很多,比如ETL、构建与失效缓存、搜索引擎索引构建等。maxwell使用起来非常简单,而且也非常好用,再此推荐给大家。
2. 与alibaba canal对比
为防止两个项目后续的变化,以下对比仅基于编写当前博文时的最新Releases版本,maxwell为1.39.4,canal为1.1.6。
说起binlog监听组件,大家可能了解更多的是阿里巴巴的canal,大厂出品,中文文档等等优势,我为什么选择了比较小众的maxwell呢? 先看一下两款组件的对比
| maxwell | canal | |
|---|---|---|
| 开源组织 | Zendesk | Alibaba |
| 活跃度 | 活跃 | 活跃 |
| 文档 | 较详细 | 较详细 |
| 开发语言 | Java | Java |
| HA | 支持,基于jgroups-raft | 支持,依赖zookeeper |
| 断点续传 | 支持 | 支持 |
| 数据格式 | JSON | 可定制,较灵活 |
| 数据落地 | kafka、支持定制 | 客户端、kafka、支持定制 |
| bootstrap 全量同步 | 支持 | 不支持 |
| 随机读取 | 支持 | 支持 |
我选择maxwel的原因主要是
- 需求是需要处理大量的历史数据的,所以maxwell的bootstrap对我来说非常方便
- maxwell只需要部署一个守护进程即可,canal需要部署server和client
- 对于canal的数据格式比较灵活,对我们来说用处不大,就算使用canal也是会使用JSON格式
- 工作原理都是基于MySQL的主从复制
3. 快速入门
MySQL配置
开启binlog
# /etc/my.cnf
[mysqld]
server_id=1
log-bin=mysql-bin
binlog_format=row
MySQL用户
需要一个具有主从复制权限的用户,并且需要有config.properties中schema_database数据库的完全访问权限,我们这里就直接使用root用户
JAVA版本
maxwell安装并启动
目录结构
下载maxwell-1.39.4.tar.gz解压后如下

命令行方式启动输出到控制台
进入目录执行如下命令
bin/maxwell --user='root' --password='root123456' --producer=stdout
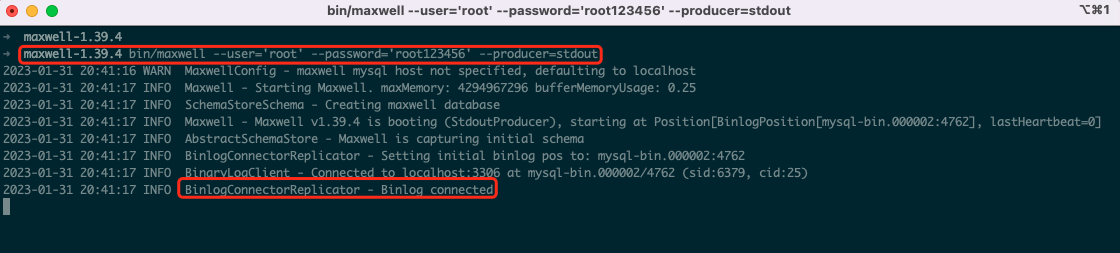
此时已经启动监听,我们来对数据库进行一些操作,可以看到控制台信息如下
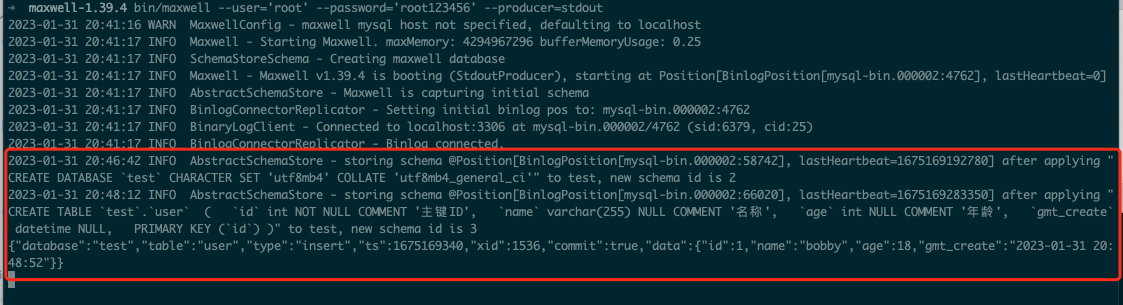
通过日志可以看出我们创建了一个名为test,字符集为utf8mb4的数据库,然后再test库中创建了一张user表,建表语句打印了出来。然后再该表中新增了一条数据。打印的信息非常清晰明了。
数据格式简介
- INSERT
{
"database": "test",
"table": "user",
"type": "insert",
"ts": 1675590121,
"xid": 234,
"commit": true,
"position": "mysql-bin.000006:410",
"data": {
"id": 7,
"name": "BobbyCao",
"age": 18,
"gmt_create": null
}
}
- UPDATE
{
"database": "test",
"table": "user",
"type": "update",
"ts": 1675590287,
"xid": 253,
"commit": true,
"position": "mysql-bin.000006:717",
"data": {
"id": 7,
"name": "BobbyCao",
"age": 28,
"gmt_create": null
},
"old": {
"age": 18
}
}
- DELETE
{
"database": "test",
"table": "user",
"type": "delete",
"ts": 1675590295,
"xid": 260,
"commit": true,
"position": "mysql-bin.000006:1035",
"data": {
"id": 7,
"name": "BobbyCao",
"age": 28,
"gmt_create": null
}
}
数据格式一摆出来,很多字段都都是不言自明的,主要说一下type是表示具体操作的类型,insert时,data中表示新增的数据;update时,data中表示修改后的数据,old表示修改之前的数据;delete时,data中表示删除前的数据。
maxwell数据库
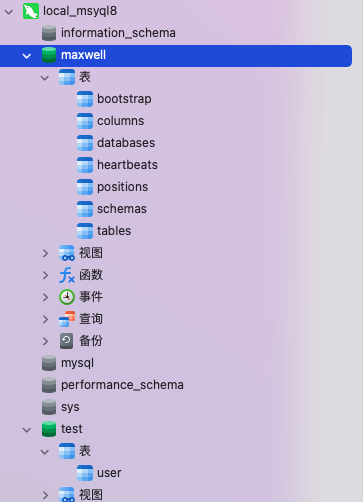
maxwell启动后,默认会创建一个名为maxwell的数据库,用于存放所需要的数据,后续会详细介绍
4. 输出到Kafka
maxwell除了支持命令行传入参数外,还支持读取配置文件、环境变量等;我们这里用配置文件的方式
前置条件
- zookeeper已有(kafka需要)
- kafka已有
配置文件
将config.properties.example文件重命名为config.properties并调整配置如下
# *** general ***
# 日志级别
log_level=info
#将数据生成到kafka,可以选择的配置有 stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis|bigquery
producer=kafka
# *** mysql配置信息 ***
host=localhost
port=3306
user=root
password=root123456
# *** kafka配置 ***
kafka.bootstrap.servers=localhost:9092
# These are 0.11-specific. They may or may not work with other versions.
kafka.compression.type=snappy
kafka.retries=0
kafka.acks=1
守护进程启动
命令行执行如下命令, --daemon表示守护进程方式启动, --config指定配置文件
bin/maxwell --daemon --config config.properties
启动后,会将日志输出到logs/MaxwellDaemon.out中
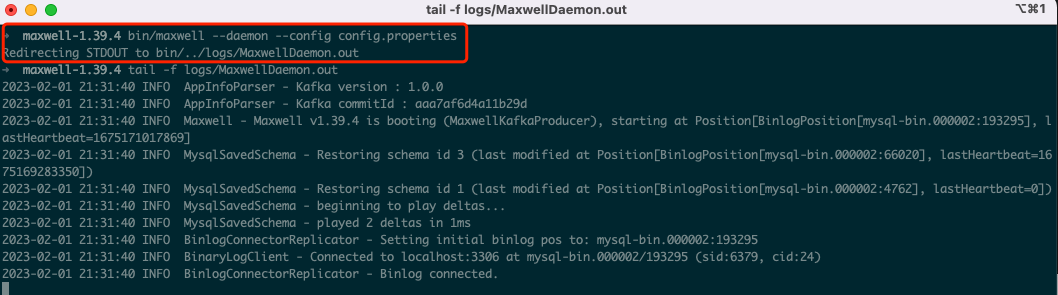
测试
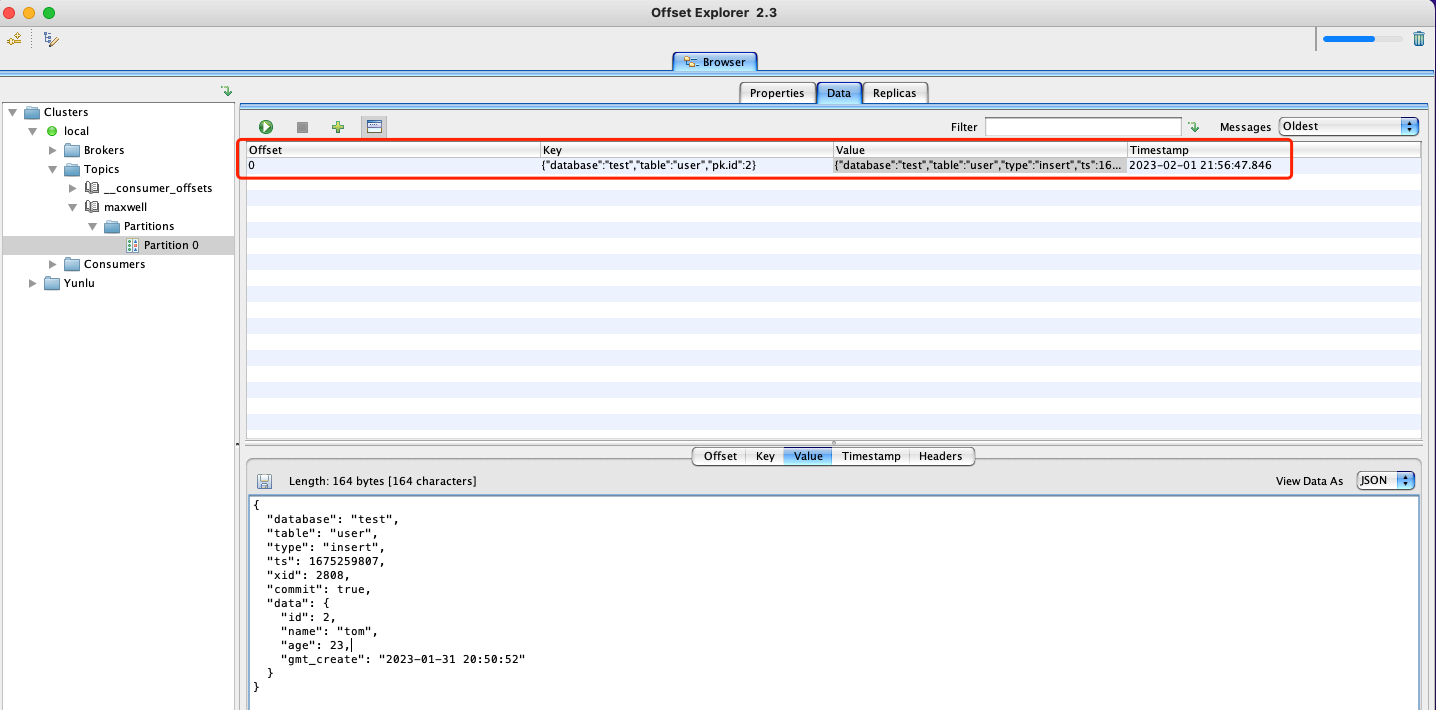
- user表中,新增数据
INSERT INTO `test`.`user` (`id`, `name`, `age`, `gmt_create`) VALUES (2, 'tom', 23, '2023-01-31 20:50:52');
- Kafka中可以看到自动创建了一个名为maxwell的topic,并生成了一条数据如下
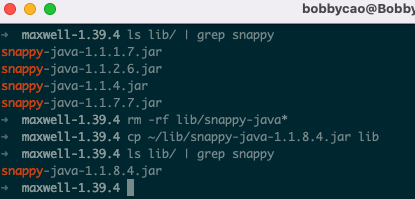
注意:如果是Mac M1芯片,可能并不会成功,日志报错如下:
2023-02-01 21:39:07 ERROR TaskManager - cause:
org.apache.kafka.common.KafkaException: org.xerial.snappy.SnappyError: [FAILED_TO_LOAD_NATIVE_LIBRARY] no native library is found for os.name=Mac and os.arch=aarch64
at org.apache.kafka.common.record.CompressionType$3.wrapForOutput(CompressionType.java:75) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.common.record.MemoryRecordsBuilder.<init>(MemoryRecordsBuilder.java:122) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.common.record.MemoryRecordsBuilder.<init>(MemoryRecordsBuilder.java:158) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.common.record.MemoryRecords.builder(MemoryRecords.java:474) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.common.record.MemoryRecords.builder(MemoryRecords.java:458) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.common.record.MemoryRecords.builder(MemoryRecords.java:406) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.clients.producer.internals.RecordAccumulator.recordsBuilder(RecordAccumulator.java:244) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.clients.producer.internals.RecordAccumulator.append(RecordAccumulator.java:220) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:806) ~[kafka-clients-1.0.0.jar:?]
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:760) ~[kafka-clients-1.0.0.jar:?]
at com.zendesk.maxwell.producer.MaxwellKafkaProducerWorker.sendAsync(MaxwellKafkaProducer.java:264) ~[maxwell-1.39.4.jar:1.39.4]
at com.zendesk.maxwell.producer.MaxwellKafkaProducerWorker.sendAsync(MaxwellKafkaProducer.java:248) ~[maxwell-1.39.4.jar:1.39.4]
at com.zendesk.maxwell.producer.AbstractAsyncProducer.push(AbstractAsyncProducer.java:93) ~[maxwell-1.39.4.jar:1.39.4]
at com.zendesk.maxwell.producer.MaxwellKafkaProducerWorker.run(MaxwellKafkaProducer.java:212) ~[maxwell-1.39.4.jar:1.39.4]
at java.lang.Thread.run(Thread.java:829) [?:?]
需要将maxwell中lib目录下低版本的snappy-java-xxx.jar替换为snappy-java-1.1.8.4.jar
动态Topic
默认情况下,会将消息写入到静态的topic,如默认的maxwell,可以根据数据库名和表名进行写入动态topic,config.properties添加如下配置即可
# 根据数据库名称和表名称动态写入topic,支持的占位符有: %{database}表示数据库名称 , %{table}数据表的名称, %{type}操作的类型,有insert/update/delete。
kafka_topic=%{database}_%{table}
重启maxwell,测试如下
输出DDL
默认情况下,maxwell是不会将DDL信息输入到kafka中,如果有需要在config.properties添加如下配置
# 是否输出ddl信息
output_ddl=true
# 将DDL变动写入到topic中,必须同时设置output_ddl=true
ddl_kafka_topic=maxwell_ddl
多分区
我们知道Kafka的Topic是支持多分区的,maxwell对此也提供了支持。但是需要我们提前将多分区的topic创建好。然后在config.properties中进行配置即可:
# *** partitioning ***
#可以根据多种方式进行分区,这里我们使用根据主键方式选择分区,支持的方式有[database, table, primary_key, transaction_id, thread_id, column]
#使用column方式时,还需要配置producer_partition_columns与producer_partition_by_fallback。
producer_partition_by=primary_key
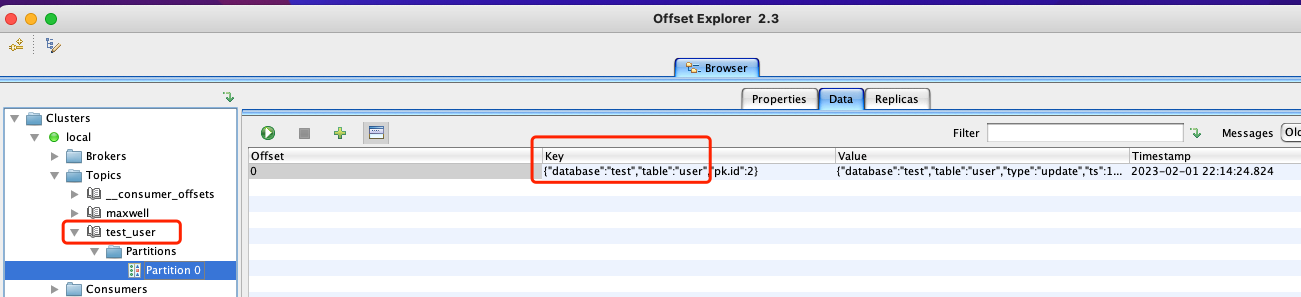
手动创建具有3个分区名为test_user的topic,进行测试如下:
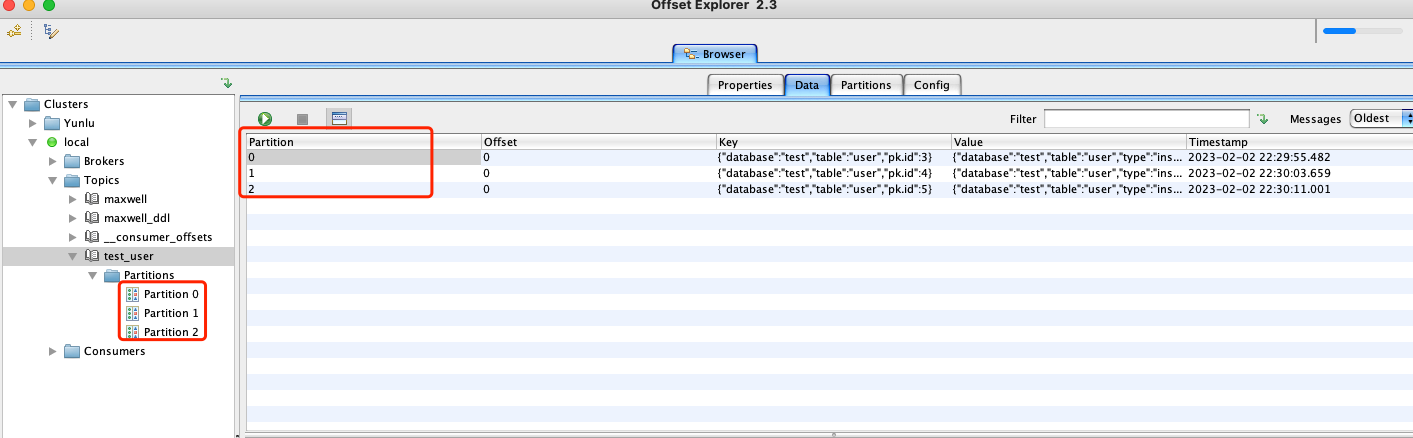
5. Filter过滤器
一般情况下,我们并不需要所有的库和表的变动信息,这个时候maxwell提供的过滤器就派上用场了,对config.properties中的filter属性进行配置:
# *** filtering ***
# 语法:<type> ":" <db> "." <tbl> [ "." <col> "=" <col_val> ]
# type 有[ "include" | "exclude" | "blacklist" ]
# db和tbl 支持正则,字符串和通配符*
# col_val:列名
filter= exclude: *.*, include: test.*
更多用法请看 https://maxwells-daemon.io/filtering/
6. MySQL相关配置
maxwell保持状态数据库介绍
上面有提到,maxwell启动时,默认会创建一个名为maxwell的数据库,如下图所示:
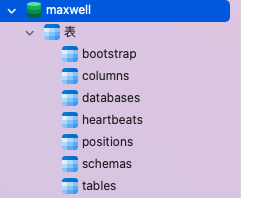
这个数据库是maxwell用来保持自己状态的mysql数据库。
| 表名 | 作用 |
|---|---|
| bootstrap | 用于初始化操作 |
| databases、tables、columns、schemas | 存放数据库的元信息 |
| heartbeats | maxwell的心跳信息 |
| positions | maxwell消费的位置信息 |
可以通过config.properties中的schema_database属性进行修改:
# maxwell保持自己状态的数据库名称
schema_database=maxwell
maxwell多实例
如果需要多个maxwell来监控一个MySQL主节点,可以通过config.properties中的已下配置来区分不同的maxwell
#maxwell实例的唯一文本标识符,默认为maxwell
client_id=bobby
#此maxwell实例的唯一数字标识符
replica_server_id=2
从不同的服务器复制和存储schema
默认情况下,我们只需要配置host即可,如果不想让maxwell的元数据数据库与抓取的数据库在一个server下,可以通过config.properties中的以下配置来进行调整
#用于存储抓去来的schema信息的数据库连接配置
host=localhost
port=3307
user=root
password=root654321
# maxwell保持自己状态的数据库名称
schema_database=maxwell_bobby
#-----------------------------
#从哪里复制binlog的数据库连接配置,不配置默认取host
replication_host=localhost
replication_user=root
replication_password=root123456
replication_port=3306
#-----------------------------
#从哪里获取schema信息的数据库连接配置,不配置,有replication_host则从这里取,没有从host里面取(大多数情况下都不需要配置,只应该在maxscale replication proxy时使用)
# schema_host=localhost
# schema_user=root
# schema_password=root654321
# schema_port=3307
GTID支持
maxwell 支持基于 GTID 的复制。通过config.properties中的
# 是否使用基于GTID模式的定位
gtid_mode=true
注意,需要MySQL服务器配置了GTID模式,my.cnf配置
# /etc/my.cnf
[mysqld]
server-id=1
#binlog配置
log-bin=mysql-bin
binlog_format=row
#开启GTID模式
gtid-mode=ON
log-slave-updates=ON
enforce-gtid-consistency=true
7. Bootstrap初始化
maxwell支持我们将数据初始化到输出中。将执行select * from table并将结果输出到我们配置落地组件中。
当我们需要初始化时,只需要在maxwell.bootstrap的表中插入数据即可如下图:
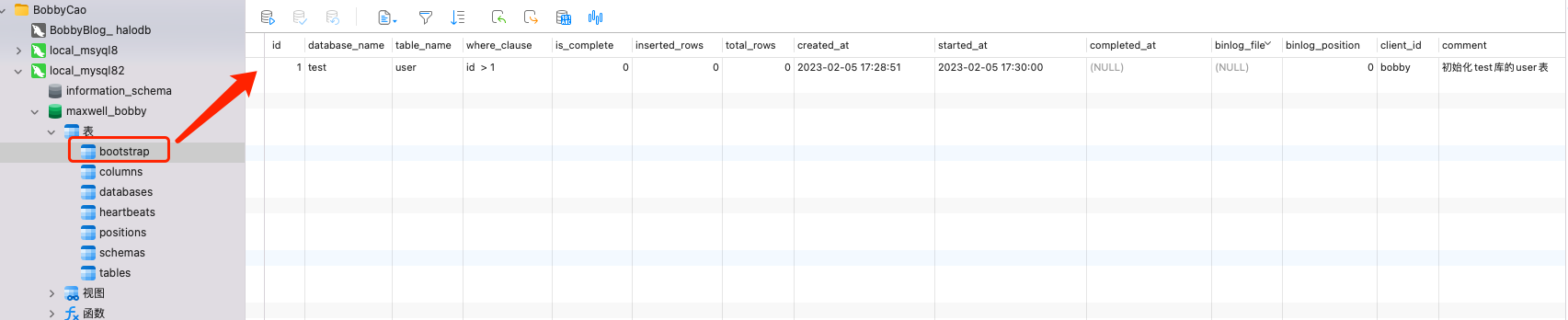
我们用到的字段主要如下
| 字段名 | 解释 |
|---|---|
| database_name | 指定数据库名称 |
| table_name | 指定表名 |
| where_clause | 可以指定where条件 |
| is_complete | 是否已经完成 |
| started_at | 可以指定时间开始执行 |
| completed_at | 完成时间 |
| client_id | 客户端ID |
还可以使用bin目录下的maxwell-bootstrap脚本从命令行执行,更多请参考 https://maxwells-daemon.io/bootstrapping/
7. 结尾
这里介绍了maxwell的大部分功能,还有很多使用方法,大家感兴趣的话,可以去maxwell官网查找。
参考文献:[Maxwell官网](https://maxwells-daemon.io/)