
关系数据库系统的查询处理
查询处理步骤
关系数据库管理系统查询处理可以分为4个阶段:查询分析、查询检查、查询优化和查询执行,如下图所示:
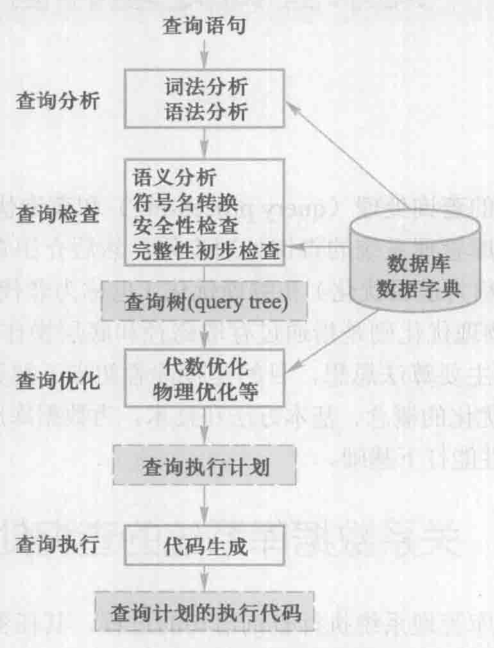
查询分析:对查询语句进行扫描、词法分析和语法分析。从查询语句中识别语言符号,如SQL关键字、属性名和关系名等,进行语法检查和分析,判断是否符合SQL语法规则。
查询检查:对合法的语句进行语义检查,根据数据字典中有关的模式定义检查语句中的数据库对象,如关系名、属性名是否存在和有效。如果是对视图的操作,把视图操作转换成对基本表的操作。还要根据数据字典中的用户权限和完整性约束定义进行检查。这时的完整性检查是初步的、静态的检查。检查通过后便把SQL查询语句转换成内部表示,即等价的关系代数表达式。关系数据库管理系统一般都用查询树,也称为语法分析树来表示扩展的关系代数表达式。
查询优化:每个查询都会有许多可供选择的查询执行策略和操作算法,查询优化就是选择一个高效执行的查询处理策略。按照优化的层次一般可以将查询优化分为代数优化和物理优化。
查询执行:根据优化器得到的执行策略生产查询执行计划,由代码生成器生成执行这个查询计划的代码,然后加以执行,回送查询结果。
实现查询操作的算法示例
这里我们来了解一下选择操作和连接操作的实现算法思想。
选择操作的实现
例:
SELECT * FROM Student WHERE <条件表达式>:
考虑<条件表达式>的几种情况:
C1:无条件;
C2:Sno = ‘20121521’;
C3:Sage >= 20;
C4:Sdept = 'CS' AND Sage > 20;
选择操作只涉及一个关系,一般采用全表扫描或者基于索引的算法。
(1)简单的全表扫描算法
对查询的基本表顺序扫描,逐一检查每个元组是否满足选择条件,把满足条件的元组作为结果输出,适合小表,不适合大表。
(2)索引扫描法
如果选择条件中的属性上有索引(例如B+树索引或hash索引),可以用索引扫描方法,通过索引先找到满足条件的元组指针,在通过元组指针在查询的基本表中找到元组。
以C2为例:如果Sno上有索引,则可以使用索引得到Sno为20121521元组的指针,然后通过指针在Student表中检索到该记录。
以C3为例:如果Sage上有B+树索引,则可以使用B+树索引找到Sage=20的索引项,以此为入口点在B+树上的顺序集上得到Sage>20的所有元组的指针,然后通过这些指针在Student表中检索到这些记录。
以C4为例:如果Sdept和Sage上都有索引,一种算法是,分别用上面两种方法找到Sdept = 'CS'的一组元组指针和Sage > 20的另一组元组指针,两组指针求交集,再到Student表中检索。另一种算法是,找到Sdept = 'CS'的一组元组指针,通过这些指针到Student表中检索,并对得到的元组进行Sage > 20的条件检查,把满足条件的元组作为结果输出。
一般情况下,当选择率较低时,基于索引的选择算法要优于全表扫描算法。但在某些情况下,例如选择率较高,或者要查找的元组均匀的分布在查找的表中,这是基于索引的选择算法的性能不如全表扫描算法。因为除了对表的扫描操作,还要加上对B+树索引的扫描操作,对每一个检索码,从B+树根结点到叶子结点路径上的每个结点都要执行一次I/O操作。
链接操作的实现
链接操作是查询处理中最常用也是最耗时的操作之一。这里简单介绍等值连接最常用的几种算法思想。
例:
SELECT * FROM Student, SC WHERE Student.Sno = Sc.Sno;
(1)嵌套循环算法
对外层循环(Student表)的每一个元组,检索内层循环(SC表)中的每一个元组,并检查这两个元组的连接属性(Sno)上是否相等。如果满足连接条件,则串接后作为结果输出,知道外层循环表中的元组处理完为止。(实际实现中数据存取是按照数据块读入内存,而不是按照元组进行I/O)
(2)排序-合并算法
这是等值连接常用的算法,尤其适合参与连接的诸表都已经排好序的情况。
- 如果参与连接的表没有排好序,首先对Student表和SC表按连接属性Sno排序。
- 取Student表中的第一个Sno,依次扫描SC表中具有相同Sno的元组,把它们连接起来。
- 当扫描到Sno不相同的第一个Sno元组时,返回Student表扫描它的下一个元组,在扫描SC表中具有相同Sno的元组,把它们连接起来。
- 重复上诉步骤直到Student表扫描完。
这样Student表和SC表都只要扫描一遍即可。如果两个表原来无序,执行时间要加上对两个表排序的时间。一般来说,对于大表,先排序后使用排序-合并连接算法执行连接,总的时间一般仍会减少。
(3)索引连接算法
- 在SC表上已建立了属性Sno的索引。
- 对Student中每一个元组,由Sno值通过SC的索引查找到相应的SC元组。
- 把这些SC元组和Student元组连接起来。
- 循环执行23,直到Student表中的元组处理完为止。
关系数据库系统的查询优化
查询优化概述
关系系统的查询优化既是关系数据库管理系统实现的关键技术,又是关系系统的优点所在。减轻了用户对系统底层选择存取路径的负担。用户就可以关注查询的正确表达式上,而无需考虑查询的执行效率如何。
系统优化后的程序通常可以比用户程序做的更好,这是因为:
- 优化器可以从数据字典中获取许多统计信息,而用户程序难以获得这些信息。
- 如果数据库的物理统计信息改变了,系统可以自动对查询重新优化以选择相应的执行计划。
- 优化器可以考虑数百种不同的执行计划,程序员一般只能考虑有限的几种可能性。
- 优化器中包括了很多复杂的优化技术,这些优化技术往往只有最优秀的程序员才能掌握。系统的自动优化相当于使得所有人都拥有这些优化技术。
关系数据库管理系统通过某种代价模型计算出各种查询执行策略的执行代价,然后选取代价最小的执行方案。集中式数据库,执行开销主要包括,磁盘存取块数(I/O代价),处理时间(CPU代价),内存空间开销,其中I/O代价是最主要的。分布式数据库需要在加上通信代价。
查询优化的总目标是选择有效的策略,求得给定关系表达式的值,使得查询代价较小。
代数优化
关系代数表达式等价变换规则
代数优化策略是通过对关系代数表达式的等价变换来提高查询效率。
查询树的启发式优化
典型的启发式规则有:
- 选择运算应尽可能先做。
- 把投影运算和选择运算同时进行。
- 把投影同其前或后的双目运算结合起来。
- 把某些选择同在它前面要执行的笛卡尔积结合起来成为一个连接运算。
- 找出公共子表达式。
物理优化
代数优化改变查询语句中操作的次序和组合,不涉及底层的存取路径。对于一个查询语句,还存在多个存取方案,它们的执行效率不同,仅仅进行代数优化是不够的。物理优化就是要选择高效合理的操作算法或存取路径,求得更好的查询计划。
基于启发式规则的存取路径选择优化
选择操作的启发式规则
对于小关系,使用全表顺序扫描,即使选择列上有索引。
对于大关系,启发式规则有:
- 对于选择条件是“主码=值”的查询,查询结果最多是一个元组,可以选择主码索引。
- 对于选择条件是“非主属性=值”的查询,并且选择列上有索引,则要估算查询结果元组数目,如果比例较小可以使用索引扫描法,否则还是使用全表顺序扫描。
- 对于选择条件是属性上的非等值查询或范围查询,并且选择列上有索引,同样要估算查询结果的元组数目,如果选择率<10%可以使用索引扫描法,否则还是使用全表顺序扫描。
- 对于用AND连接的选择条件,如果涉及这些属性组合索引,则优先采用组合索引扫描方法;如果某些属性上有一般索引,则可以使用上面C4说过的索引扫描方法,否则还是使用全表顺序扫描。
- 对于用OR连接的析取选择条件,一般使用全表顺序扫描。
连接操作的启发式规则
- 如果2个表已经按照顺序连接属性排序,则选用排序-合并算法。
- 如果一个表在连接属性上有索引,则可以选用索引连接算法。
- 最后可以选用嵌套循环算法,选择其中较小的表,作为外表。
基于代价估算的优化
基于代价的优化方法要计算各种操作的执行代价,并选出具有最小代价的执行计划(它与数据库的状态密切相关,据字典中存储了优化器需要的统计信息)。
参考文献:
数据库系统概论-第5版[王珊,萨师煊]